Sign In
Create your first automation in just a few minutes.Try Studio Web →
Apache Open NLP Activities
by YouTube
0
Activity
<100
Summary
Summary
Natural Language Processing Toolkit from Apache Open NLP platform
Overview
Overview
Activities:
- Detect Language
- Detect Sentences
- Named Entity Recognition
- POS Tagger
- Tokenize Sentences
NOTE: The activities work only for English language models.
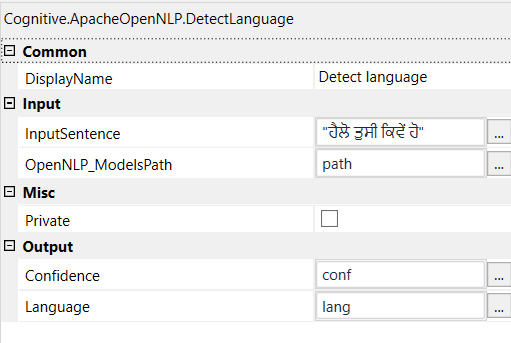
The OpenNLP Language Detector classifies a document in ISO-639-3 languages according to the model capabilities.
Input Parameters:
- Input Sentence - String
- OpenNLP_ModelsPath - Path of the OpenNLP Models folder
Output Parameters:
- Confidence - Confidence of language extraction
- Language - Detected language
Detect Sentences
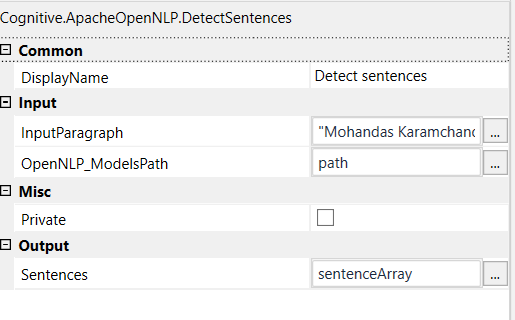
The OpenNLP Sentence Detector can detect if a punctuation character marks the end of a sentence or not. In this sense a sentence is defined as the longest white space trimmed character sequence between two punctuation marks. The first and last sentence make an exception to this rule. The first non whitespace character is assumed to be the beginning of a sentence and the last non whitespace character is assumed to be a sentence end.
Input Parameters:
- InputParagraph - String
- OpenNLP_ModelsPath - Path of the OpenNLP Models folder
Output Parameter:
- Sentences - Array of sentences found from the InputParagraph
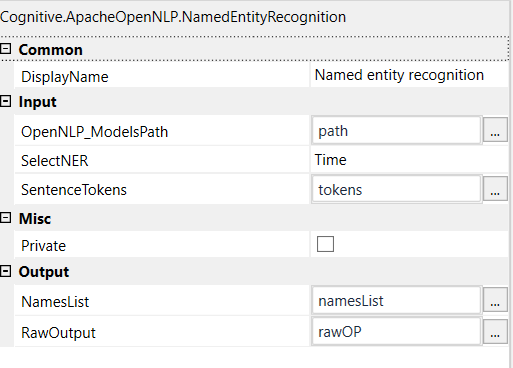
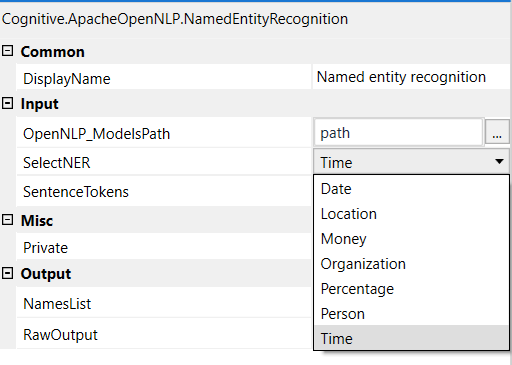
The Name Finder can detect named entities and numbers in text. To be able to detect entities the Name Finder needs a model. The model is dependent on the language and entity type it was trained for. The OpenNLP projects offers a number of pre-trained name finder models which are trained on various freely available corpora. They can be downloaded at our model download page. To find names in raw text the text must be segmented into tokens and sentences. A detailed description is given in the sentence detector and tokenizer tutorial. It is important that the tokenization for the training data and the input text is identical.
Input Parameters:
- SelectNER - Select one of the NER models from the dropdown
- SentenceTokens - Tokenized sentence
- OpenNLP_ModelsPath - Path of the OpenNLP Models folder
Output Parameters:
- NamesList - List of entities found in the SentenceTokens
- Rawoutput - Raw op of the NER
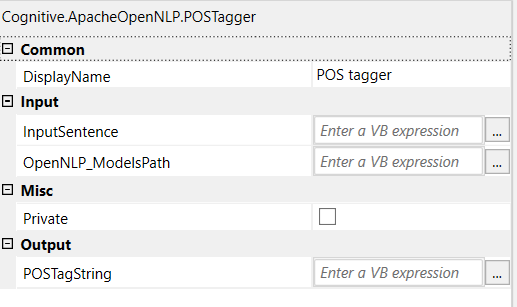
The Part of Speech Tagger marks tokens with their corresponding word type based on the token itself and the context of the token. A token might have multiple pos tags depending on the token and the context. The OpenNLP POS Tagger uses a probability model to predict the correct pos tag out of the tag set. To limit the possible tags for a token a tag dictionary can be used which increases the tagging and runtime performance of the tagger.
Input Parameters:
- InputSentence - Input sentence
- OpenNLP_ModelsPath - Path of the OpenNLP Models folder
Output Parameter:
- POSTagString - POS Tagged string
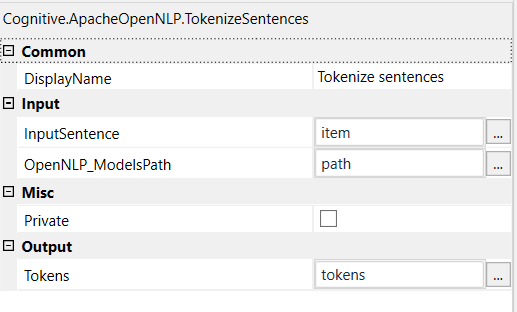
The OpenNLP Tokenizers segment an input character sequence into tokens. Tokens are usually words, punctuation, numbers, etc.
OpenNLP offers multiple tokenizer implementations:
- Whitespace Tokenizer - A whitespace tokenizer, non whitespace sequences are identified as tokens
- Simple Tokenizer - A character class tokenizer, sequences of the same character class are tokens
- Learnable Tokenizer - A maximum entropy tokenizer, detects token boundaries based on probability model
Most part-of-speech taggers, parsers and so on, work with text tokenized in this manner. It is important to ensure that your tokenizer produces tokens of the type expected by your later text processing components.
With OpenNLP (as with many systems), tokenization is a two-stage process: first, sentence boundaries are identified, then tokens within each sentence are identified.
Input Parameters:
- InputSentence - Input sentence
- OpenNLP_ModelsPath - Path of the OpenNLP Models folder
Output Parameter:
- Tokens - Tokens Array
Features
Features
Out of the box NLP Activities which don't need any server to be setup like in Stanford NLP. This also has a lot of options for customization and training custom models as compared to Stanford NLP.
Additional Information
Additional Information
Dependencies
NOTE: No dependency is required to be installed in UiPath Studio. The dependencies mentioned below are just for information purpose: OpenNLP nuget pakage: Install-Package OpenNLP -Version 1.3.5 System.Runtime.Caching nuget package :Install-Package System.Runtime.Caching
Code Language
Visual Basic
Runtime
Windows Legacy (.Net Framework 4.6.1)
Technical
Version
1.0.0Updated
February 18, 2020
Works with
All previous and current versions of UiPath Studio
Certification
Silver Certified
Support
UiPath Community Support
Resources